2019 in review
@rauchg|January 2, 2020 (6y ago)68,244 views
This post is a quick summary of the evolution of our company, our open-source work, interesting news and lessons in product design and engineering throughout 2019.
#Static is the new Dynamic
Throughout 2019 we have continued to see the growth of the JAMstack. The idea is quite simple: Any website or app you build and deploy will use the stack of client-side JavaScript, APIs, and Markup.
By now, client-side JavaScript (like React and Vue) and APIs (like REST and GraphQL) are quite mainstream, but my favorite part is the assumption that your markup will be static.
First: Why Static?
- Static is globally fast. When you deploy, we can hoist all your static assets to a global CDN network. By removing the server from the equation, we can also maximize availability by reducing and even altogether eliminating cache misses.
- Static is consistently fast. It gives you "O(1) TTFB", which is a fancy way of saying you get stable and predictable latency to the first byte of the screen. Always, because no code, servers, sockets, or databases are involved.
- Static is always online. This should not be surprising, but servers frequently go down and involve complex rollout schemes [1], while static files are trivially cacheable and simple to serve. The odds of you getting paged during the holidays because a "static asset can't be served from a CDN" are basically zero.
Second: Really, Static? I have dynamic needs.
Servers are not going away, but they are moving around and hiding.
-
Static Site Generation (SSG) can be thought of moving around the servers and taking them away from the hot path. Instead of putting a server in between the user's request and the response, we compute the response ahead of time.
This subtle shift pays back handsomely. One, anything that could go wrong, goes wrong at build time, maximizing availability. Two, we compute once and re-use, minimizing database or API load. Three, the resulting static HTML is fast.
-
Client-side JS and APIs that get executed later, once the static markup and code is downloaded and executed, allow for effectively infinite dynamism.
Pre-computing all pages is not always possible [2], nor desirable. For example, when dealing with data that is not shared between all users and we wouldn't want to cache at the edge [3].
#Next.js, the next frontier
Next.js has continued to grow in adoption and now powers the likes of Hulu, Tencent News, Twitch, AT&T, Auth0 and the list goes on.
Thanks to its simplicity, it's a compelling all-in-one solution for the full straddle of JAMstack: from a static landing page, to very large websites, to fully dynamic applications.
The "secret sauce" continues to be its simple pages/ system inspired by cgi-bin and throwing .php files in a FTP webroot.
A page is just a React component. The simplest Next.js app is pages/index.js which will serve the route /:
export default () => <div>Hello World</div>
But here's what happened in 2019:
- Pages can be defined like this:
pages/r/[subreddit].js, which will allow you to define dynamic path segments with no configuration or custom servers. - If a given page is static and has no server-side data props,
next buildwill output just "boring" static.html😄 - If you define static data props, we can fetch data at build time for a certain page, but crucially also "explode" dynamic path segments into many discrete pages.
- If you create
pages/api/myApi.js, you are basically defining a serverless function that can return anything you want, which will most likely be a JSON API.
In short, Next.js is now a comprehensive, hybrid framework, supporting the full spectrum of JAMstack with a per-page granularity.
| Role | Provided by |
| --- | --- |
| J | Client-side JS injected via React Hooks (state, event listeners, effects) |
| A | API pages inside the pages/api directory. |
| M | Pages with no data dependencies (like the simple example above) or pages with static data deps that trigger build-time static site generation. |
Furthermore, Next.js has been uncompromising in its commitment to backwards-compatibility. Servers (SSR) are still fully supported and no apps have been harmed as part of this evolution.
#Deploying the Jamstack
We think there's enormous value in empowering teams to instantly build and deploy JAMstack websites, with no servers or infra to manage or configure.
True to our style, deploying any static site (like just a index.html) or more complex and full-featured frameworks like Next.js, Gatsby, Gridsome, … begins with just:
$ vc
✅ Preview: https://blog-p2pe8jedz.now.shnpm i -g vercel to installThe Vercel platform gives you a comprehensive workflow with built-in CI/CD and global CDN, that are carefully optimized for production-grade dynamic sites.
A salient feature is the transition we are seeing away from code review into deployment preview.
Code review is undeniably important (specially speedy code review), but nothing beats teams collaborating by sharing URLs to the actual sites that are being worked on and experiencing them directly.
By setting up a Git integration, every single git push gets its own live deployment URL. Thanks to the simplifications granted by the model, deployments are orders of magnitude faster to build, deploy and serve than when using servers or containers, which only adds to the great team-wide collaboration experience.
#The Deploy URL, the Center of Gravity
An interesting consequence of being able to deploy so fast and so frequently is that it completely changes testing and quality assurance.
Every URL like https://blog-p2pe8jedz.now.sh, a preview deployment of this blog as I was writing this post, is a real, production-like environment just like the rauchg.com one.
This means that instead of running tests that make all kinds of assumptions about the environment (like mocking it), we can instead test the real thing. As real as it gets.
The most natural form of "e2e testing" is experiencing the end result itself by visiting the URL. Sharing it with customers, co-workers and your manager.
But in 2019, we also witnessed the incredible power of delegating automated testing against this URL to other services.
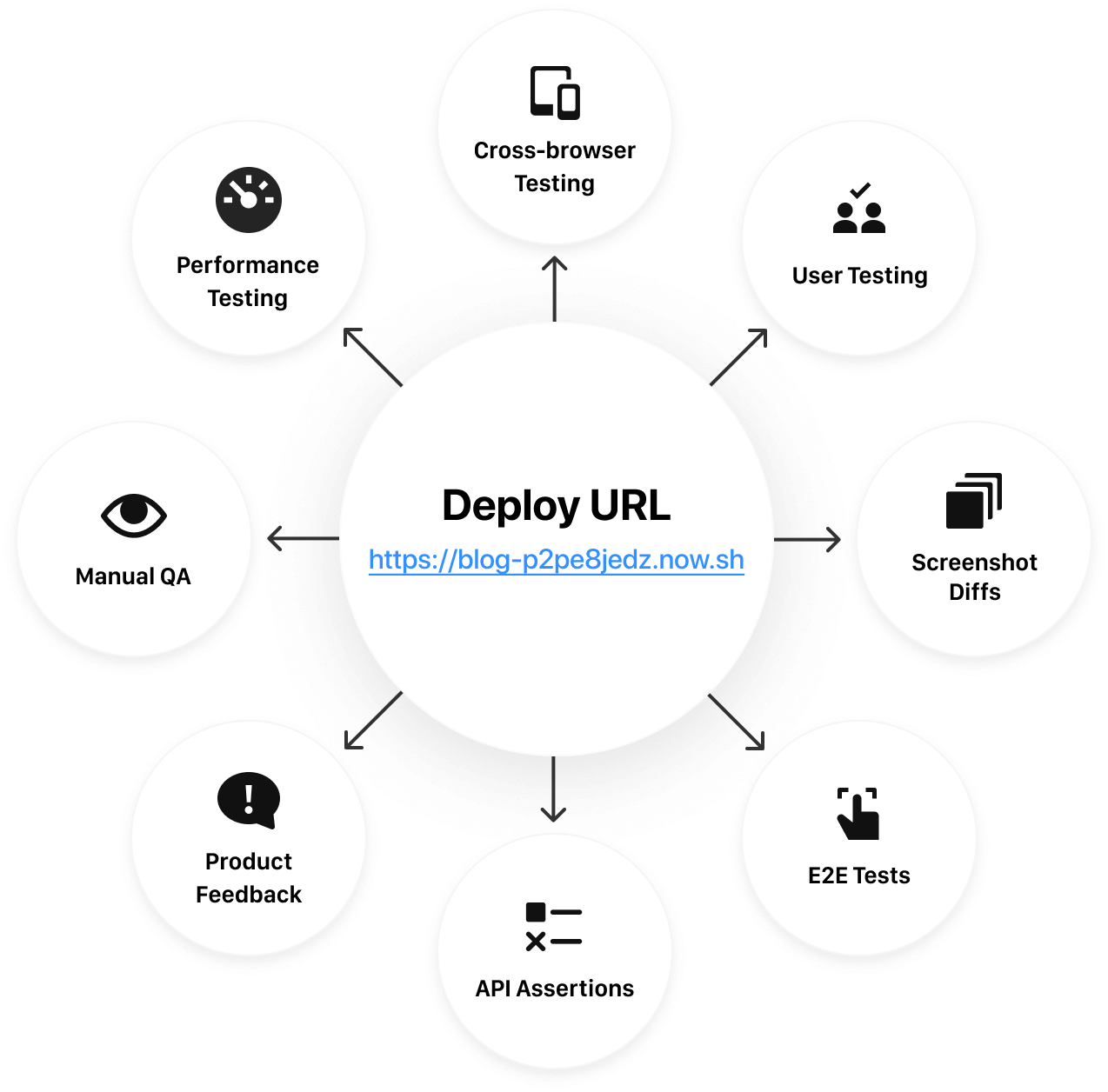
When you install our GitHub app, we don't just register a "Check" like other CI providers in the pull request. We also say: this is a deployment, here is the URL.
In parallel, a series of assurance checks can then be run against that prod-ready URL. This includes, but is not limited to:
- Browser Testing, simulating user journeys and real interactions
- Screenshot Testing, to automatically prevent visual regressions
- HTTP Assertion Testing, requesting APIs or pages and verifying the outputs
- Manual QA, with designated reviewers who approve the PR.
#Flaky Tests mean Flaky UX
When it comes to testing, I've found myself referencing this insight quite frequently:
As developers, we might sometimes be too quick to place the blame on tools (or the aether) and just press the restart button.
But the truly important question to ask is: what if it had been one of your customers, instead of an automated test? Would they not have had a flaky experience? Would it be ok to tell them to press F5 and try again?
#Serverless means infrastructure that upgrades itself
Serverless is an exciting trend that has resisted a universal definition. Asking what serverless really means probably got you 5 different answers in 2018, and 10 different answers in 2019.
However, a defining characteristic that I've become a fan of is that serverless means your infrastructure upgrades itself.
This includes everything from upgrading the operating system, to patching the system's OpenSSL, to bumping the version of the Node.js function runtime.
This wonderful effect is particularly pronounced for databases. It's one thing to upgrade the infrastructure of stateless code execution, but dealing with data is a whole new challenge that I'm glad we no longer have to deal with [4].
#Hyrum's Law
I recently learned about Hyrum's Law, which states:
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.
Which obviously has a relevant xkcd as prior art:

#Microservices increase complexity and reduce availability
Microservices allow you to break down a service's dependencies into independently deployable units.
The problem? The assurances that were previously statically guaranteed by the compiler or runtime for a given piece of software are now gone. What was before a unit becomes a distributed system.
Not only are microservices harder to manage than, say, a static blob of code together with its dependencies inside a function or container, but odds are they are also less available.
This should already be obvious from at least one angle: introducing an additional network hop can only make things worse.
Kevin Mahoney has provided a new neat mathematical illustration of the availability problem of inter-connecting services:
Take the example where service C depends on services A and B[…]
If A has an availability of 0.8 (80%) and B 0.95 (95%), C will have a best case of 0.8 (80%), an average case of 0.8 × 0.95 = 0.76 (76%), and a worst case of 1 - ((1 - 0.8) + (1 - 0.95)) = 0.75 (75%)
Making your serverless functions "monolithic" offers a compelling solution to this problem. Statically bind the dependencies of each function (Next.js API routes and the Go compiler do this) and avoid introducing unneeded service hops of your own.
#Native means Platform Fidelity, not Native Code
The word "native" has always bothered me. No one can seem to agree on a definition, but we all agree that "native apps" are always optimal.
Many people are quick to write off attempting to write a desktop app or mobile app in JavaScript on the basis that it's not native. Sometimes the word is used to indicate that JS can't compile down to an executable binary that's native to the platform.
I propose the following alternative definition of native: an app that behaves to the quality standards of the platform it's deployed to.
This explains why Electron has been so successful in re-purposing the web stack to the Desktop platform. A well engineered Electron app will give you "native" platform fidelity, regardless of programming language.
To achieve platform fidelity, it's obvious one must have access to the platform APIs. This makes mobile web "apps" a non-starter in achieving the coveted "native" status, especially on iOS Safari.
It has nothing to do with performance or JS and HTML, and everything to do with being altogether unable to deliver on the standards of what a real app can do on the platform^[5].
A React Native app can achieve full platform fidelity (it can exhibit great performance with solid engineering while being unconstrained in API capabilities). Crucially, like Electron, it offers a cohesive development experience, a universal programming language, a shared module and component system, seamless updates and faster deployments, with both ~~macOS~~ iOS and ~~Windows~~ Android support to boot.
#Settings are for successful products
Great products usually start with a dead simple onboarding journey that minimizes or entirely eliminates options.
From a startup evolution or product management perspective, another way of considering this wisdom is: absolutely resist adding options until substantial evidence of success without them exists.
#Game engineering continues to show the way
When React was being introduced, it was interesting to hear that the inspiration wasn't previous libraries like jQuery, but rather an altogether different system:
React gets some of its inspiration from how game engines achieve awesome performance in their rendering pipeline
What striked me about this wonderful talk about how Marvel's Spiderman was created is how much more we can learn.
The most striking part of it is the careful planning around the well-understood limits of the platform that lead to a great user experience.
Today, at large, this kind of rigor is absent from web engineering practice, even though the boundaries exist and are well documented.
So far, we have mostly been suggested limits. Examples include: warnings in webpack's colorful output for oversized bundles, scoring systems like WebPageTest and Lighthouse, and the constant reminder and enticement that more speed means more success for your business (in the form of better Google rankings and the Amazon 100ms rule).
AMP, although controversial, is a systematic, rather than suggested answer to the performance problem. It's very hard, maybe impossible, to create a slow AMP experience, due to the smart constraints and built-in well-optimized components [6].
Along the same lines, I'm optimistic about the introduction of Never-Slow Mode, which is a more general solution than AMP, with a shared focus on performance. Like AMP on Next.js, I reckon it will be a mode many will be interested in adopting.
Notion: the fanciest# datastructure
When announcing Trello, Joel Spolsky famously conjectured:
The great horizontal killer applications are actually just fancy data structures.
Spreadsheets are not just tools for doing “what-if” analysis. They provide a specific data structure: a table. Most Excel users never enter a formula. They use Excel when they need a table. The gridlines are the most important feature of Excel, not recalc.
In 2019, I fell in love with Notion, which you can think of an all-in-one company/personal wiki + full MS Office-like suite.
That you could have one tool to solve such a wide array of problems sounds impossible, let alone for a small startup. But the secret to its success lies in its elegant, flexible and user-transparent datastructure.
Notion's datastructure could be explained as: a mutable, realtime graph of documents structured as a list of known blocks.
All apps are backed by datastructures, but the critical ingredient seems to be the ability to perform direct manipulation on them, which requires that the topology is completely transparent and obvious to the end user.
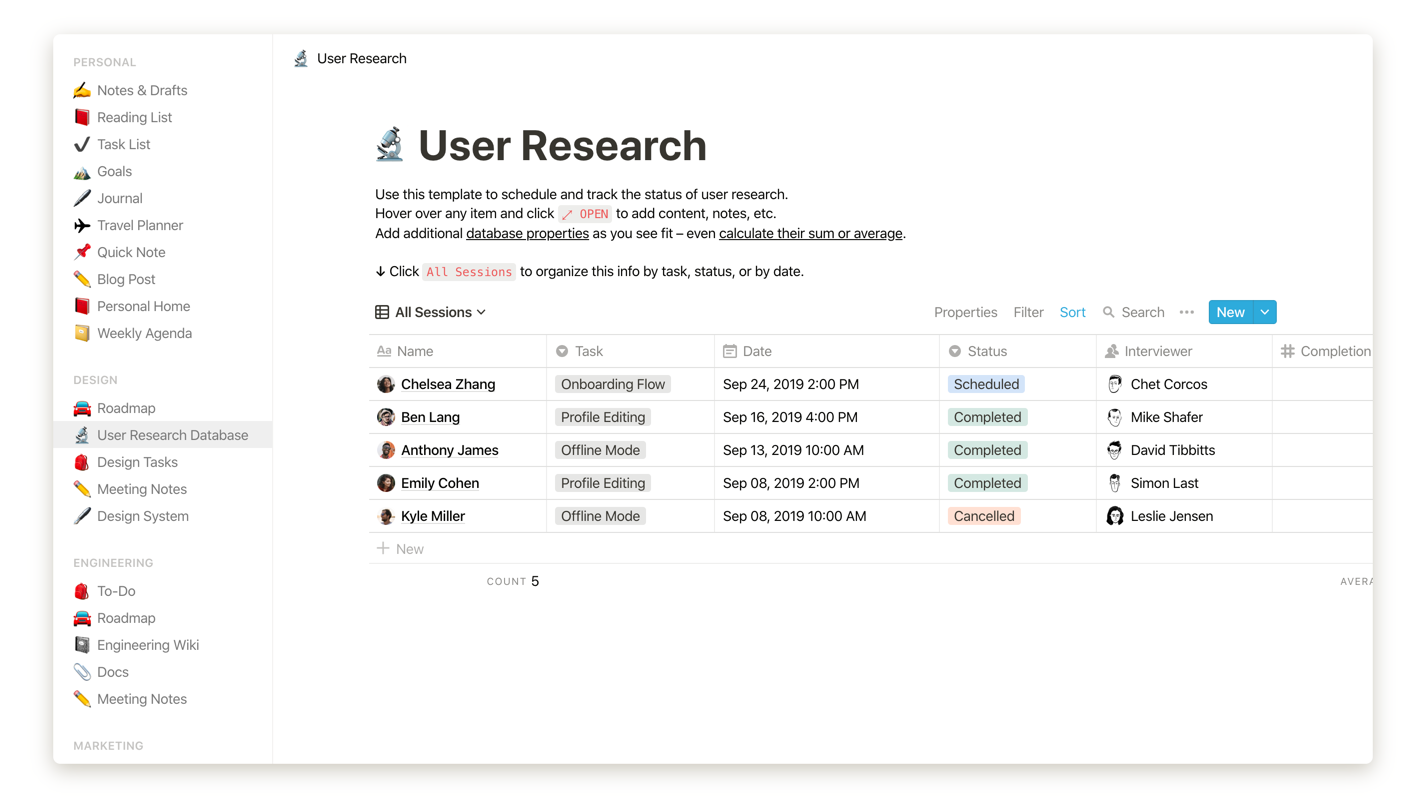
On the left hand side, Notion's sidebar puts you in direct contact with the graph the documents are organized as. You are free to arrange pages into trees and sub-trees of your choosing. On the right hand side, the different block types are trivial to create, edit, re-arrange and most importantly: combine.
In the old world, a table is not thought of as a block, but a document that you boot Excel or Google Spreadsheets to visualize. Instead, combining headings, paragraphs, tables, databases, lists, etc to your liking inside any document, which you link to and open with the same realtime collaborative app, strikes me as a revolution whose time has finally come.
#Breaking: inputs should look like inputs
This one should not come as much of a shocker, but alas.
It only took 600 participants, 2 designers, 1 researcher to confirm: inputs should look like inputs.

#Shared CDNs have their caches busted
A remarkable change to anyone who was hoping we could "share React" or "share jQuery" by an ad-hoc agreement of a common CDN and URL inside a <script> tag.
The whole idea has been busted.
#All Code is Wrong
Another year, another great opportunity to remember that most of your code is likely wrong. We got to hear this from the famed creator of Fornite:
As a reminder, if it's not fast and reliable, then it is wrong. When things are not fast, it's like an implicit confirmation that they are wrong. Deeply wrong:
[…] The slowness is like an off smell. I don’t trust the application as much as I would if it didn’t slow down on such a small text file. 5,000 words is nothing. Faith is tested: It makes me wonder how good the sync capabilities are. It makes me wonder if the application will lose data.
Speed and reliability are often intuited hand-in-hand. Speed can be a good proxy for general engineering quality
— Craig Mod on Fast software, the Best software
#Get busy demoing
I continue to marvel at the incredible product-improving and life-improving power of giving demos frequently. Giving frequent demos was an essential part of creating the iPhone:
#NoCode and LowCode are real, and they are on a collision course
It's easy to dismiss the hype around NoCode and LowCode as just hype, but I think there's a lot to it.
For one: the less code you write, the easier to maintain, and the less likely that it will be wrong. Next.js is a clear example of this. Our data-fetching [7] library SWR is another. Zero-config deployments, another.
I suspect 2020 and the years to come will see LowCode solutions (like React, Vue, Svelte...) continue to gain traction by making it simple and succinct to share UI and behavior (e.g.: as UI components or hooks).
We will also see the rise of visual tools to bring those primitives together more efficiently, including the capability to bring reusable components from either a canonical component system or a global shared library.
#More Hardware that merges with our Software
After ARM gave us a JS-optimized instruction, Samsung is giving us key-value optimized SSDs.
#Everything is code. Roll everything like code
Applying a configuration change? Review it, roll it gradually and most importantly: mistrust it, just like you mistrust code.
#Webassembly is faster than you thought
For a while I've been excited about the universal potential of webassembly. It turns out it's even better than I anticipated: when disabling sandboxing, webassembly can match 95% the speed of native code.
WebAssembly isn’t just a way to run C++ in a web browser, it’s a chance to reinvent how we write programs, and build a radical new foundation for software development
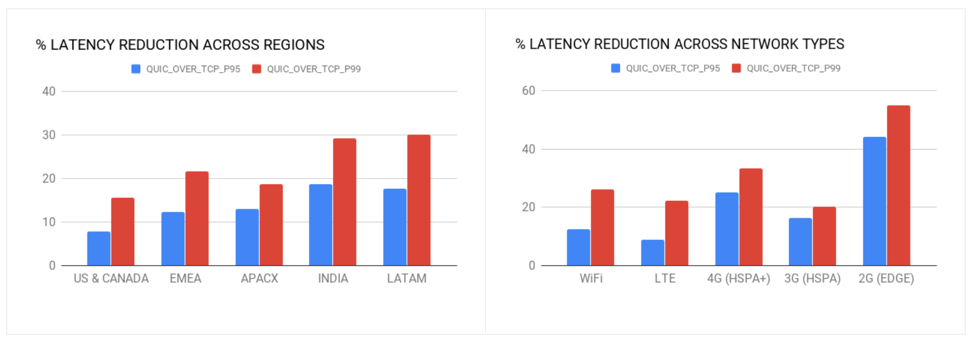
#QUIC (HTTP/3) is faster than you thought
Uber deployed QUIC at scale, obtaining remarkable results.
The results from this experiment showed that QUIC consistently and very significantly outperformed TCP in terms of latency when downloading the HTTPS responses on the devices. Specifically, we witnessed a 50 percent reduction in latencies across the board, from the 50th percentile to 99th percentile.
#We are interested in stablecoins not bitcoin…
… seems to be the new "we like blockchain not bitcoin".
The president of the European Central Bank said the word "stablecoin" in 2019. That was a twist I wasn't expecting.
#Zoom just works better
Zoom went public. Its differentiator? It works better.
#Google's engineering practices go open-source
Google's engineering practices were open-sourced on GitHub. My favorite part? The emphasis on speedy code-review:
At Google, we optimize for the speed at which a team of developers can produce a product together, as opposed to optimizing for the speed at which an individual developer can write code. The speed of individual development is important, it’s just not as important as the velocity of the entire team.
Further, Google's cryptography practices were "open-sourced" in a tweet:
#AWS shares how they build ultra-reliable services
AWS architect Colm MacCárthaigh shares 10 patterns for controlling the cloud and ensuring its reliability:
1. ^ Servers can be so hard to roll out without downtime that a keynote atthis year's KubeCon starts with the glaring admission: "Noticing your customers receive 503's every now-and-then?". By not needing to rotate pods, shut down containers, handle signals, wait for grace periods, configure and execute liveliness probes… static is also faster and safer to roll.
2. ^ When the set of pages to pre-compute is too large and would make buildtimes prohibitive, it's still probably a good idea to pre-computeyour most critical public pages, and do the rest asynchronously.
3. ^ Crucially, websites and apps that serve the same static markup and codeto all users have a drastically simpler security model, which means…static is also more secure.
4. ^ Our infrastructure makes use of CosmosDB, a serverless database byMicrosoft Azure with remarkably (consistent) low-latency and effectivelyinfinite horizontal scalability.
5. ^ Perhaps the most fundamental way in which a mobile web app on iOS Safaricannot ever be "native" like an app is in the way the viewportsize is dynamic and shifts as you scroll to reveal different toolbars.
6. ^ Speaking of native, Iintuit that, rather than native code generation, native mobile apps owetheir generally better performance to the a rich standard library ofwell-optimized UI components. Go, when compared to Node.js+npm, hassimilarly demonstrated the success of a great stdlib for common,performance-critical needs.
7. ^ What you do in one line of SWR, you tend to do in a few dozen lines of Redux.


